
 min read
min read How do you achieve 98% accuracy on your churn model? That’s easy – predict that NO ONE will ever churn and…tada! 2% of the population will churn in the coming period. By predicting that everybody will stay, you will reach 98% accuracy. However, you will also completely mess up your goal. This is why, in any classification model, accuracy is not what matters.
Gaining a competitive edge by limiting the churn of your valuable customers is a holy grail for businesses everywhere. It’s vital to use the right tools that offer you the precision you need to target the right people at the right time and avoid loss of business. Churn propensity models aim to predict the churn probability for each customer in a defined period of time. The challenge is to carefully define the business goals so that they impact the model and vice versa. This is a rare opportunity where data science impacts business outcomes directly. To achieve this, data scientists need to understand the business model and business impact. By doing so, you can fine-tune your models, carefully built over massive data and smart techniques, to address the exact targets the business people need and affect customer engagement.
How do we achieve this?
The data scientist must have a clear goal of the score they want to achieve, which needs to reflect the goal of the project. When developing a churn model, the first question is simply how do you want to communicate with your potential churning customers. For example, with the same budget, you can reach many more customers by email than by phone. Next, every churn model, and every classification model, must achieve the right balance between what is known in the data science world as precision and recall.
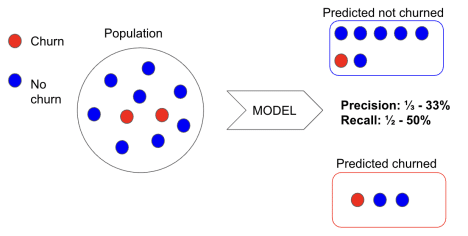
Precision is the proportion of actual churners in the predicted churner population. A precision score of 60% means that out of 100 predicted churners, 60 actually churn.
Recall is the proportion of actual churners that we predicted with our model. A recall of 30% means that out of 100 churners, our model caught 30 of them.
So for a phone campaign, we need high precision because we want every call, which can be costly in terms of resources allocated, to be effective in achieving its result. A less expensive email campaign allows us to be less precise in identifying a larger number of churners.
For instance, when you have a small group of well-paid financial advisors who are compensated based on retention success, you want to make sure that every call they make is effective in the sense that they’re targeting customers who are actually in need of financial advice. You want to avoid a situation where they call people randomly, wasting their valuable time and reducing their enthusiasm and focus.
We also have to ensure that our outreach to potential customers doesn’t result in contacting those who are not at risk and have the opposite effect of causing them to churn as a result of the call.
So the strategy must define the balance between precision and recall based on clear business goals while ensuring that the score reflects the model based on specific business needs. Ultimately, every customer that is “saved” by implementing a churn model is valuable revenue for your business and increases your competitiveness in the market.
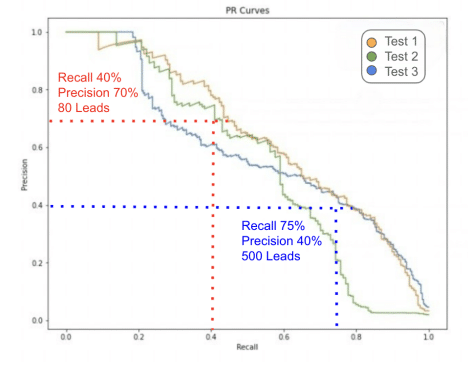
Good data science practice is to balance precision and recall based on the needed business outcome. In this case, various business requirements might lead to very different data science models with different accuracy measures.

 min read
min read

 min read
min read
 min read
min read


